- 首页 > 生活知识 > 潮科技 > >
下降|神经网络成“病毒软件”新宿主!国科大最新研究:嵌入恶意软件后,性能下降不足1%( 二 )
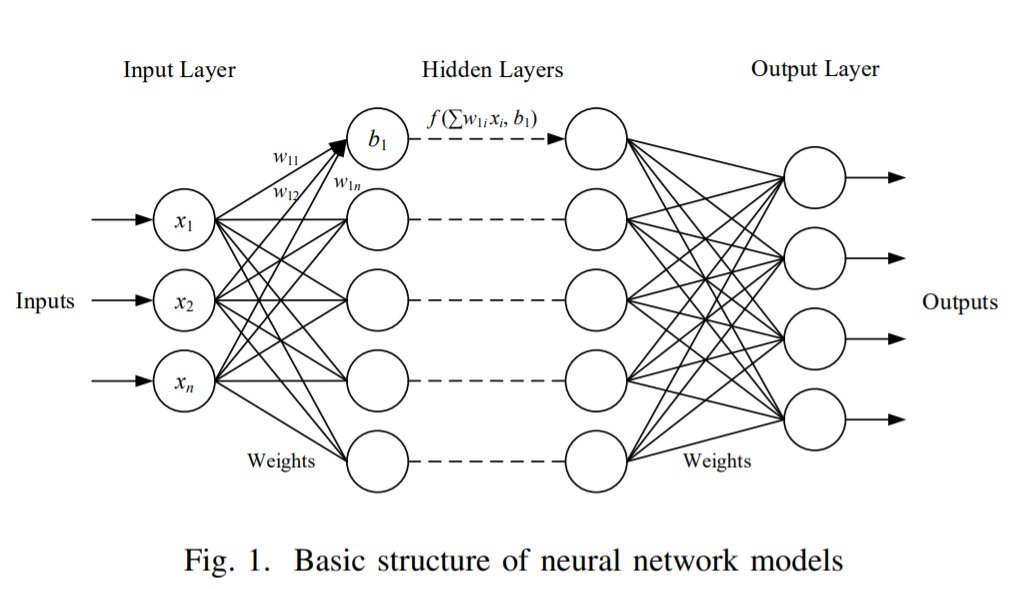
文章插图
总结来看,基于神经网络模型的恶意软件呈现出以下特点:- 通过神经网络模型和反汇编,可以隐藏恶意软件的特征,使其逃避检测。
- 由于冗余神经元的存在和神经网络的泛化能力,经修改后的神经网络模型在不同的任务中仍保持其性能。
- 在特定任务中,神经网络模型的规模很大,使大量恶意软件传播成为可能。
- 不依赖于其他系统漏洞,嵌入恶意软件的模型可通过供应链的更新渠道或其他方式传递,不会引起防御者的注意。
基于以上因素, 随着神经网络的应用越来越广泛,这种方法将在未来的恶意软件传输中得到普遍应用。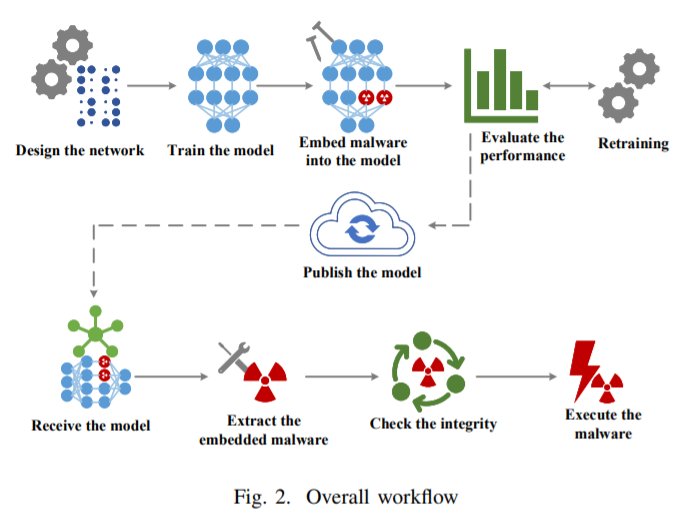
文章插图
为了防止嵌入恶意软件的模型性能受到影响,攻击者通常遵循以下步骤:1.设计神经网络。为了确保嵌入更多的恶意软件,攻击者通常会引入更多的神经元。 2.选择合适的现有模型,或者使用数据集对网络进行训练,获得性能更好的模型。3.选择合适的层嵌入恶意软件。嵌入恶意软件后,攻击者需要评估模型的性能,如果模型的性能损失超出可接受范围,需要使用数据集重新训练模型以获得更高的性能。一旦准备好模型,攻击者就可以使用供应链污染(supply chain pollution)等方法将其发布到公共存储库或其他地方。接收者假定是在目标设备上运行的程序,可以下载模型并从模型中提取嵌入的恶意软件。在更新模型后,通常是先根据预定义规则提取恶意软件,然后进行安全性检查,最后再等达到预定义条件后运行恶意软件。具体过程如下:如上所述,神经元中的参数将会被恶意软件替换。由于每个参数都是一个浮点数,攻击者需要将恶意软件中的字节转换为32位浮点数,且保持在合理的时间间隔内。为了让接收者能够正确提取恶意软件,攻击者会采用一套规则将恶意软件嵌入其中。本文提供了一个嵌入算法:对于要嵌入的恶意软件,每次读取3个字节,并将前缀添加到第一个字节,然后将字节转换为具有big-endian格式的有效浮点数。如果剩余的样本少于3个字节,则添加“\x00”进行填充。在嵌入模型之前,这些数字会被转换成张量。最后在神经网络模型和指定的层中,通过替换每个神经元的权值和偏差,对神经元的进行修改。其中,每个神经元中的连接权重用来存储转换后的恶意软件字节,偏差用来存储恶意软件的长度和哈希值。接收者的提取过程与嵌入过程相反。接收端需要提取给定层的神经元参数,并将参数转换成浮点数。这些浮点数再转换成big-endian字节格式,去掉字节前缀,得到二进制字节流。然后,根据第一个神经元长度记录的偏差,接收者可以集成恶意软件。此外,接收者可以通过比较恶意软件的散列值与偏差记录中的散列值来验证提取过程。在这项工作中,研究人员假定通信信道具有启动防病毒安全扫描的能力,如果模型不安全可以将其拦截,并且模型性能一旦超过设定的阈值也会向终端用户发出警报。