本科生|南科大本科生用AI跨越数千年解读甲骨文
【 本科生|南科大本科生用AI跨越数千年解读甲骨文】甲骨文因年代久远、字形变化多样、无传世文献可供对照等因素,对其的识别一直是考古学面临的重要难题。
针对甲骨文识别这一学术难题,南方科技大学6位本科生运用图像和文本处理、深度学习算法、开发创新的神经网络算法和生成对抗算法,结合甲骨文的形态、语义、上下文关联等知识,实现甲骨文文字的自动识别、生成和检索目标。
文章插图
甲骨文,又称“契文”、“龟甲兽骨文”、“甲骨卜辞”或“殷墟文字”,指中国商朝晚期王室用于占卜记事而在龟甲或兽骨上契刻的文字,是现存中国王朝时期最古老的一种成熟文字,最早出土于距今三千多年前的河南省安阳市殷墟遗址。
识别甲骨文一直是困扰学术界的难题,为了解决这一问题,南方科技大学2018级本科生曾鸣、杨睦圳、鲁昊天、汪炜、席睿翎和2017级张舒煜等6名同学,在人文社科唐际根老师、计算机系刘江老师以及研究团队章晓庆、胡玙璠、钟雯的指导下,以CS330《多媒体信息处理》课程学到的知识和技能为基础,尝试用AI解读甲骨文。
据介绍,他们首先建立了甲骨文数据库,将已识别的甲骨文图像及其对应汉字收入库中,目前已完成558个单字、1.8万多张图像的录入。接着,采用经典的深度残差神经网络(ResNet)模型实现手写甲骨文图像识别的任务;然后,选择pix2pix生成对抗网络(GAN)作为生成甲骨文的自动方法,用于增加样本多样性和生成一些未知甲骨文,其中基本网络采用U-Net结构;最后,利用检索算法将未知甲骨文图像与已有的甲骨文对比,从数据库检索出未知甲骨文图像。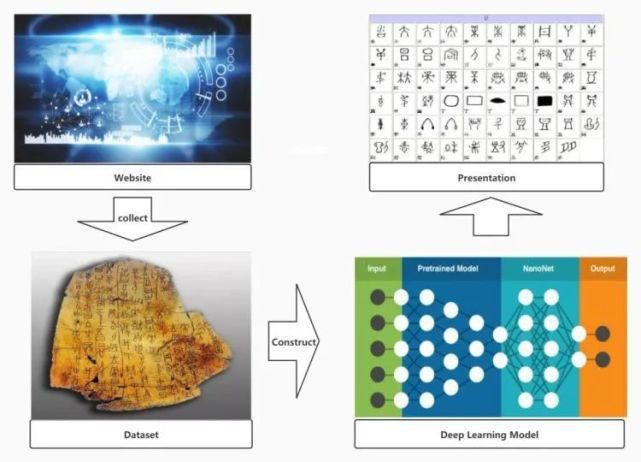
文章插图
本项目创新地开发多媒体信息处理和人工智能技术应用于甲骨文的识别和生成,以考古学研究需求为导向,以多媒体信息处理和人工智能创新算法为核心,充分融合南方科技大学考古研究与多媒体人工智能算法创新的科研实力,体现了跨学科交叉融合的魅力与力量,实现了跨越学科边界的思维碰撞与技术共享。目前,合作团队已经着手开发可用于展示和互动的微信小程序,希望将甲骨文的识读面向大众,提升大众对甲骨文的理解。
项目小组组长曾鸣说:“在甲骨文识别项目中,我们小组学习了甲骨文相关历史和研究现状,并把人工智能技术应用到甲骨文。这次人文研究和计算机技术的结合,让我们体会到交叉学科研究的魅力!”项目成员杨睦圳则表示,虽然项目遇到了数据库不足等诸多挑战,但“在构建甲骨文识别与检索系统的过程中,我们自己动手去收集与处理数据,认识了各种各样有趣的甲骨文字,收获颇丰”。
深圳商报/读创首席采访人员 吴吉
编辑 吴怡漪
监制 吴吉
校审 谭录岗
点击在看,让更多朋友看到!
- 央视公开“支持”倪光南?柳传志该醒悟了
- 东南亚|MIUI13深度使用报告,这还是我认识的MIUI吗?网友评价很真实
- 凌晨,南京市雨花台区地震!
- 卢照邻 战城南
- 一嗨租车|倪光南最辉煌的时光是不是和柳传志的那段“蜜月期”?
- 联想|新华社发视频力挺联想,司马南阵脚乱了
- 会议|北飞书,南钉钉,企微声音听不清?
- 河南消费者协会主任就辛巴燕窝事件发声。老狗称李四拉不了。
- 联想|司马南没告诉你们,当年联想的使命根本不是研发,而是赚钱养计算所
- 香菇|南漳:云上购年货助农迎新春