但机器如何学习世界模型呢?这归结为两个问题:我们应该使用什么学习范式来训练世界模型?世界模型应该使用什么架构?
对于第一个问题,我的答案是 SSL(自监督学习)。一个例子是让机器观看视频,暂停视频,然后让机器学习视频中接下来会发生什么的表示。在这样做的过程中,机器可以学习大量关于世界如何运作的背景知识,可能类似于婴儿和动物在生命的最初几周和几个月内的学习方式。
对于第二个问题,我的答案是一种新型的深度宏架构,我称之为分层联合嵌入预测架构(H-JEPA)。简单解释,JEPA 不是预测视频剪辑的未来帧,而是学习视频剪辑的抽象表示和剪辑的未来,以便后者能够基于对前者的理解很容易地预测。这可以使用非对比 SSL 方法的一些最新发展来实现,特别是我和我的同事最近提出的一种称为“VICReg”的方法。
文章插图
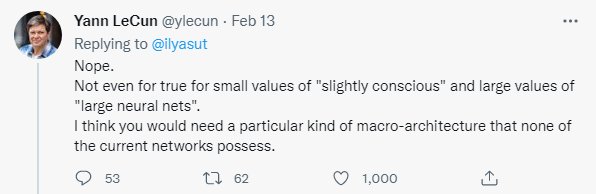
文章插图
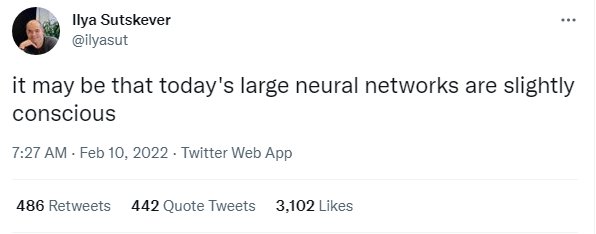
IEEE Spectrum:几周前,你回复了在OpenAI任职的 Ilya Sutskever 的一条推文,他在推文中推测,今天的大型神经网络可能有意识。你的回答是响亮的“不”。在您看来,构建一个有意识的神经网络需要什么?那个系统会是什么样子的?
LeCun:首先,意识是一个非常模糊的概念。一些哲学家、神经科学家和认知科学家认为这只是一种幻觉,我非常接近这种观点。
但我对导致意识错觉的原因有一个猜测。我的假设是,我们的前额叶皮质中有一个单一的世界模型“引擎”。该世界模型可根据当前情况进行配置。我们是帆船的舵手;我们的世界模型模拟了我们船周围的空气和水流。我们建了一张木桌;我们的世界模型想象切割木头和组装它们的结果,等等。
我们的大脑中需要一个模块,我称之为“配置器”,它为我们设定目标和子目标,配置我们的世界模型来模拟当前的情况,并启动我们的感知系统以提取相关信息并丢弃赘余信息。监督配置器的存在可能是让我们产生意识错觉的原因。但有趣的是:我们需要这个配置器,因为我们只有一个世界模型引擎。如果我们的大脑足够大,可以容纳许多世界模型,我们就不需要意识。所以,从这个意义上说,意识是我们大脑局限的结果!
IEEE Spectrum:自监督学习在元宇宙的构建中可以扮演什么角色?
LeCun:深度学习在虚拟世界中有很多具体的应用,比如 VR 护目镜和 AR 眼镜的运动跟踪,捕捉和重新合成身体运动和面部表情等等。
元宇宙中人工智能驱动的新创意工具有很多机会,可以让每个人在虚拟世界和现实世界中创造新事物。但元宇宙也有一个“纯AI”的应用:虚拟 AI 助手。我们应该有虚拟的 AI 助手,可以在日常生活中帮助我们,回答我们的任何问题,并帮助我们处理每天轰炸我们的海量信息。为此,我们需要我们的 AI 系统对世界如何运作(无论是物理还是虚拟)有一定的了解,有一定的推理和计划能力,以及一定程度的常识。简而言之,我们需要弄清楚如何构建可以像人类一样学习的自主 AI 系统。这需要时间。但是Meta在这条赛道上已经走了很长时间。

文章插图
- 软件|为什么教老人用电子产品这么难:他们无法理解抽象符号建立的逻辑
- 图灵奖得主Yann LeCun最新访谈:人工智能面临的三大挑战
- 抽象|设计产品架构的基本方法
- 美无处不在!看看摄影师如何表现自然界中的抽象美
- Java|java培训:如何在Java中选择接口类和抽象类
- 删除|注意你的抽象,伙伴
- vt|当抽象文化遇到虚拟主播,评论区成了文豪的聚集地
- y1993珍贵录像:32岁的LeCun向世界亲自展示了首个CNN
- LeCun在线访谈:我的深度学习之路
- 业务|如何把现实中的业务抽象成产品?