文章插图
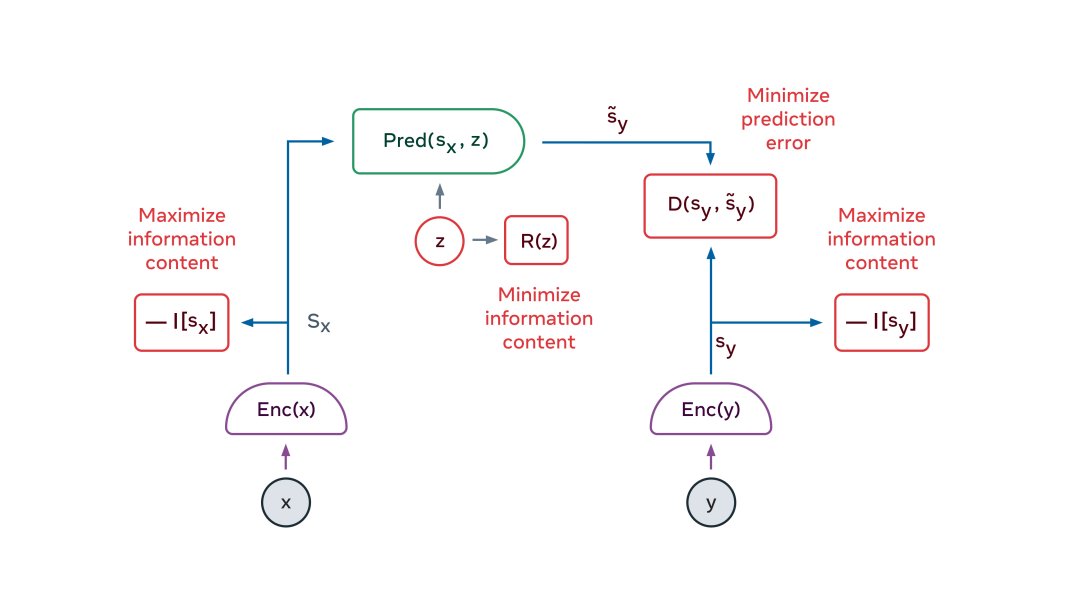
JEPA 的美妙之处在于它自然地产生了输入的信息抽象表示,消除了不相关的细节,并且可以执行预测。这使得 JEPA 可以相互堆叠,以便学习具有更高抽象级别的表示,可以进行长期预测。
例如,一个场景可以在高层次上描述为“厨师正在制作可丽饼”。它可以预测厨师会去取面粉、牛奶和鸡蛋,将食材混合,把面糊舀进锅里,将面糊油炸,并翻转可丽饼,然后不断重复该过程。在较低层次的表达上,这个场景可能是倒一勺面糊并舀均匀,且将其铺在锅周围。一直持续到每一毫秒的厨师的手的精确轨迹。在低层次的手部轨迹上,我们的世界模型只能进行短期的准确预测。但在更高的抽象层次上,它可以做出长期的预测。
文章插图
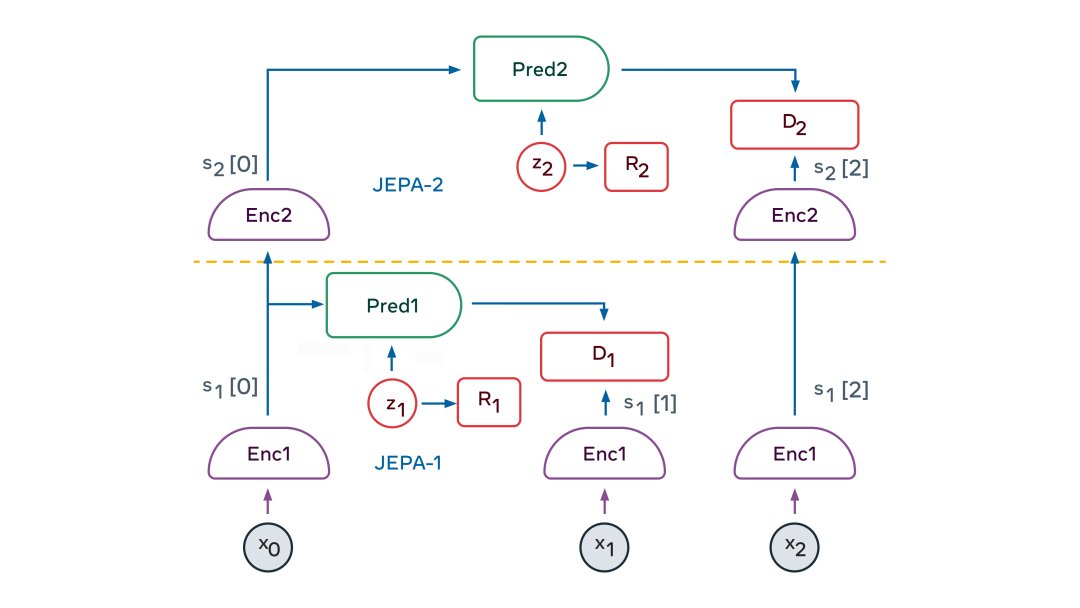
分层 JEPA 可用于在多个抽象级别和多个时间尺度上执行预测。训练方式主要是通过被动观察,很少通过互动。
婴儿在出生后的头几个月主要通过观察来了解世界是如何运作的。她了解到世界是三维的,知道有些物体会摆在其他物体的前面,当一个物体被遮挡时,它仍然存在。最终,在大约 9 个月大的时候,婴儿学会了直观的物理学——例如,不受支撑的物体会因重力而落下。
分层JEPA 的愿景在于它可以通过观看视频和与环境交互来了解世界是如何运作的。通过训练自己来预测视频中会发生什么,它可以生成对世界的分层表示。通过在世界上采取行动并观察结果,世界模型将学会预测其行动的后果,进而能够推理和计划。
文章插图
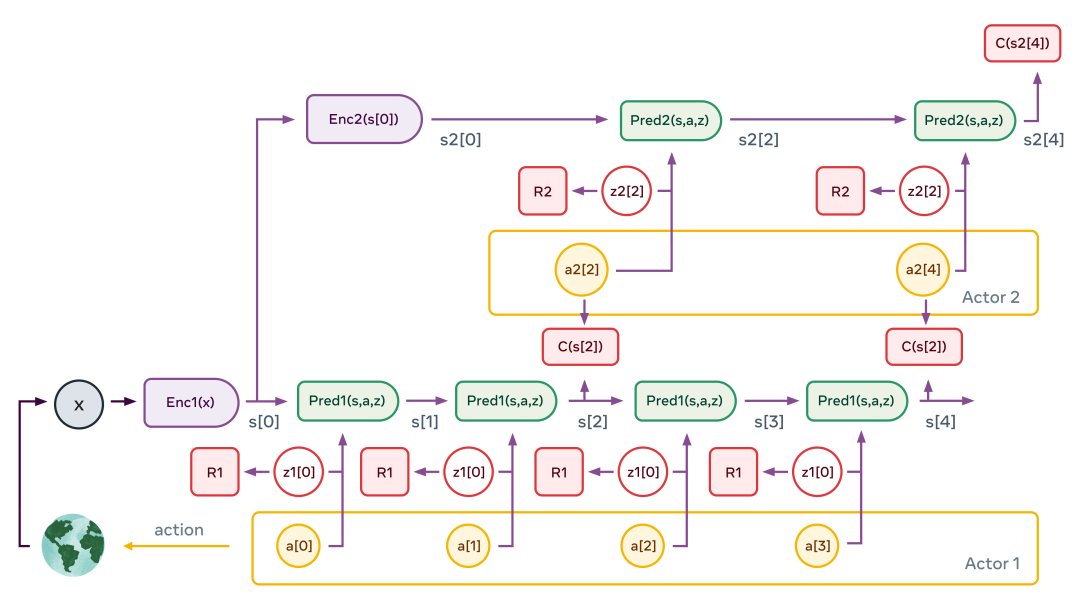
一个典型的感知-行动情节如上。该图说明了两级层次结构的情况。感知模块提取世界状态的分层表示(图中 s1[0]=Enc1(x) 和 s2[0]=Enc2(s[0]))。然后,在假设二级行动器提出的一系列抽象动作的情况下,多次应用二级预测器来预测未来状态。行动器优化二级动作序列以将总成本最小化(图中的C(s2 [4]))。
这个过程类似于最优控制中的模型预测控制。对第二级潜在变量的多个绘图重复该过程,这可能会产生不同的高级场景。由此产生的高级动作并不构成真正的动作,而只是定义了低级状态序列必须满足的约束(例如,食材是否正确混合?)。它们确实构成了子目标。整个过程在低层重复:运行低层预测器,优化低层动作序列以将上层的中间成本最小化,并对低层潜在变量的多个绘图重复该过程。一旦该过程完成,智能体将第一个低级动作输出到效应器,整个情节可以重复。
如果我们成功构建了一个这样的模型,那么所有的模块都是可微的,因此整个动作优化过程可以使用基于梯度的方法来执行。
- 软件|为什么教老人用电子产品这么难:他们无法理解抽象符号建立的逻辑
- 图灵奖得主Yann LeCun最新访谈:人工智能面临的三大挑战
- 抽象|设计产品架构的基本方法
- 美无处不在!看看摄影师如何表现自然界中的抽象美
- Java|java培训:如何在Java中选择接口类和抽象类
- 删除|注意你的抽象,伙伴
- vt|当抽象文化遇到虚拟主播,评论区成了文豪的聚集地
- y1993珍贵录像:32岁的LeCun向世界亲自展示了首个CNN
- LeCun在线访谈:我的深度学习之路
- 业务|如何把现实中的业务抽象成产品?