知识|产品视角下的知识图谱构建流程与技术理解( 七 )
文章插图
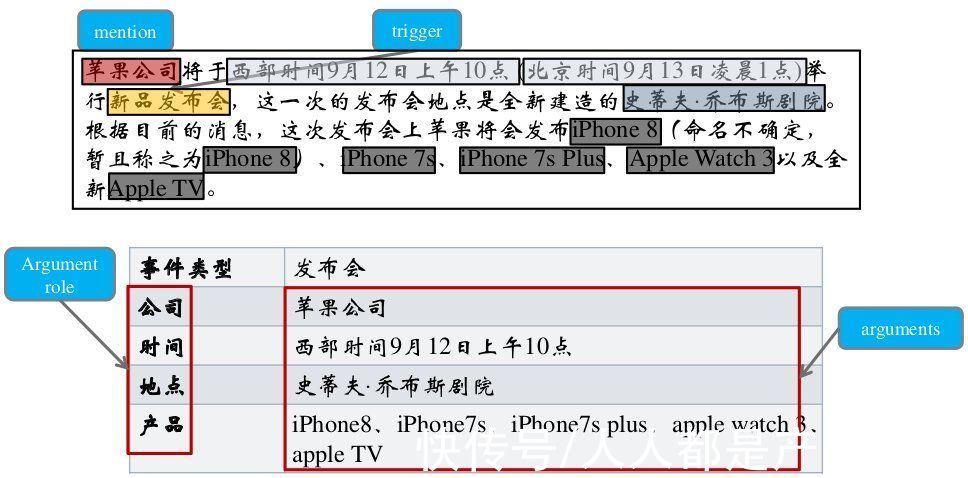
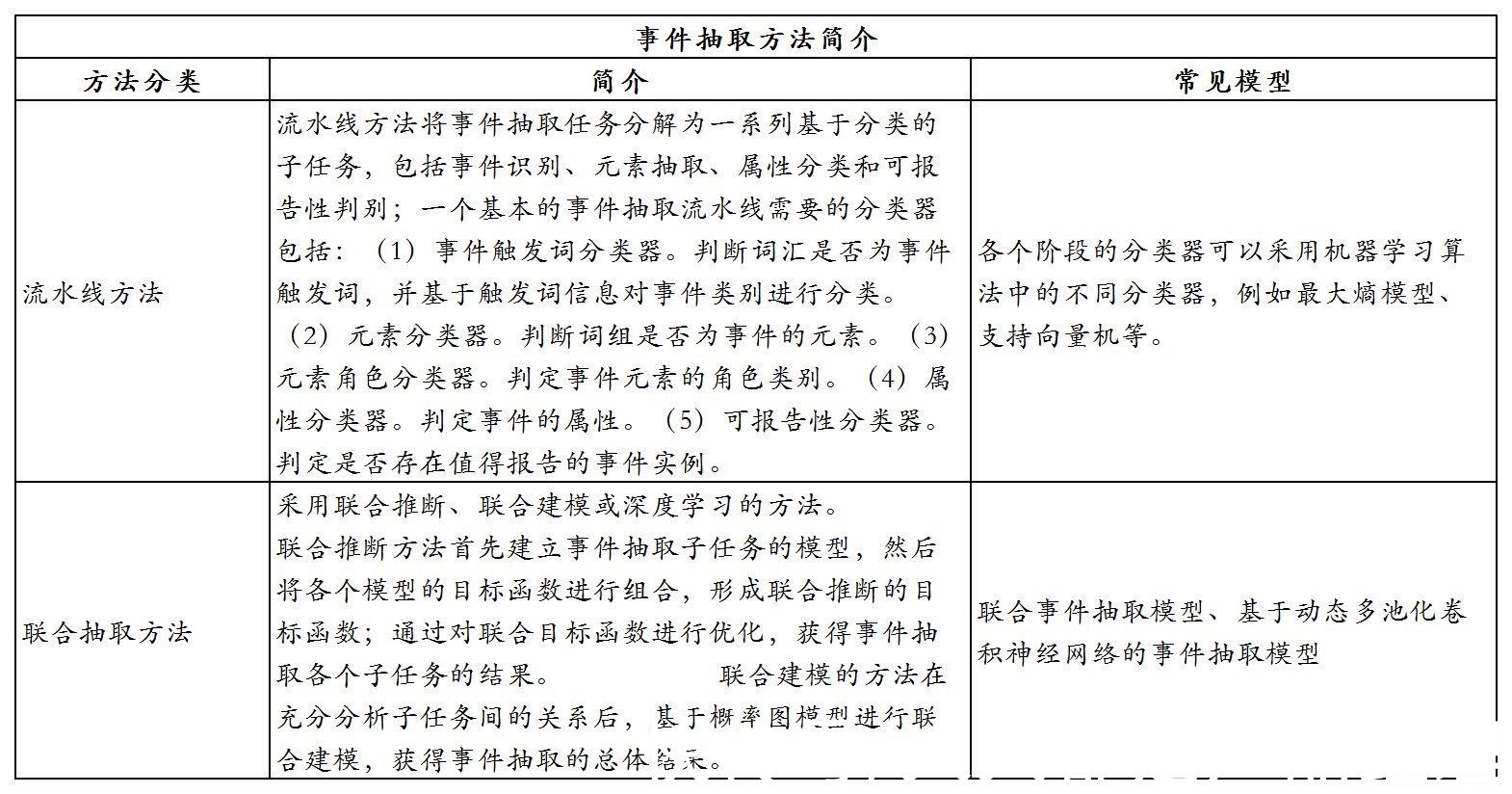
事件抽取是指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等,如下图:
文章插图
图:事件抽取
文章插图
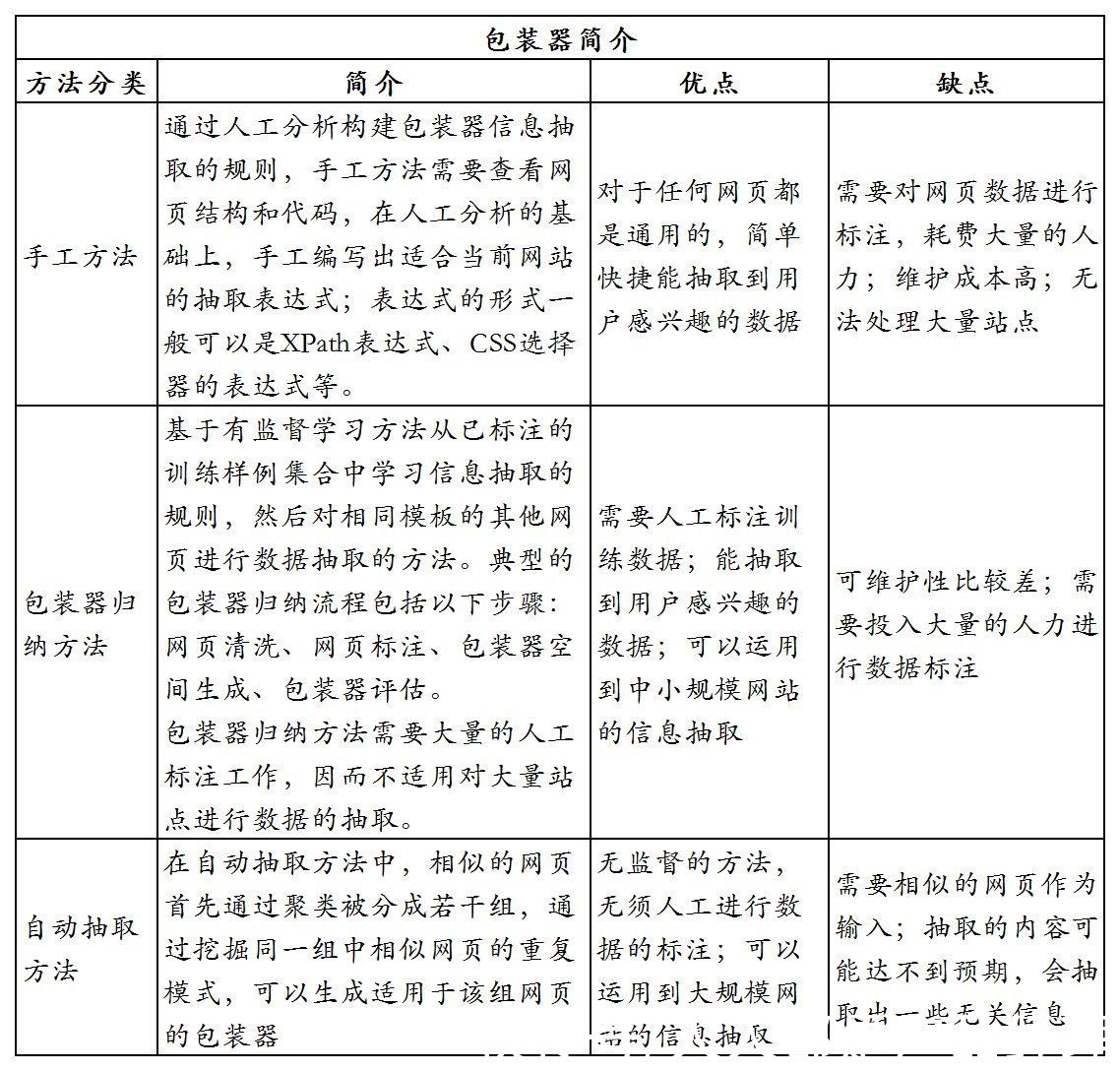
半结构化数据抽取主要是从网页中提取,一般通过包装器实现,包装器是能够将数据从HTML网页中抽取出来,并将它们还原为结构化数据的软件程序。
文章插图
结构化的数据抽取一般是按照规则映射,W3C的RDB2RDF工作组于2012年发布了两个推荐的RDB2RDF映射语言:DM(Direct Mapping,直接映射)和R2RML。
直接映射规范定义了一个从关系数据库到RDF图数据的简单转换,将关系数据库表结构和数据直接转换为RDF图,关系数据库的数据结构直接反映在RDF图中,基本规则包括:
- 数据库中的表映射为RDF类;
- 数据库中表的列映射为RDF属性;
- 数据库表中每一行映射为一个资源或实体,创建IRI;
- 数据库表中每个单元格的值映射为一个文字值(LiteralValue);
- 如果单元格的值对应一个外键,则将其替换为外键值指向的资源或实体的IRI。
数据库的直接映射中,生成的RDF图的结构直接反映了数据库的结构,目标RDF词汇直接反映数据库模式元素的名称,结构和目标词汇都不能改变。
而通过使用R2RML,用户可以在关系数据上灵活定制视图。
已经有一些标准和工具支持将数据库数据转化为RDF数据、OWL本体等,如D2RQ、Mastro、Ultrawrap、Morph-RDB等。
七、知识融合构建一个大规模,高质量的知识图谱是需要很大工作量的,实际使用中,如果能够把已有的知识图谱和其他成熟的知识图谱联合使用,或者多个系统信息交互使用,将大大提升知识图谱的规模和效能。
目前,解决本体异构、消除应用系统间的互操作障碍是很多知识图谱应用面临的关键问题之一。
知识融合是指使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,将同一个概念或实体的描述信息关联起来。
简而言之,将多个知识图谱用一套规范联合使用起来,就叫知识图谱融合(也叫知识融合),虽然益处显而易见,但融合也存在很多问题,其中最主要的问题是异构问题。
其实异构就是不同图谱对于同一个事物的认识和表示存在冲突,没法把不同图谱中的本体和实例一一对应起来,从而造成使用出现错误。
造成异构的原因有很多,典型的如:
- 人类的知识体系非常复杂;
- 一些知识还受到个人主观看法的影响;
- 前沿知识会不停的发展变化;
- 同一领域有不同组织构建自己的知识库,交叉领域中的交叉知识往往是独立构建的等等。
- 同一领域内往往存在着大量本体,且它们描述的内容在语义上往往有重叠或关联;
- 本体在表示语言和模型上具有差异;
- 同名的实例可能指代不同实体;
- 不同名的实例可能指代同一实体。
知识图谱中的异构形式主要可以划分为两个层次:
- |我依然是iPhone 6P的“钉子户”,尽管它成了古董产品
- |2022年换手机首选这款产品,性价比高运行速度快,用三四年没问题
- 基础层|B端决策类产品|关键信息密度提升设计
- 凌锋|追求更好用的轻薄本,还得看准Evo认证,这两款产品全都有
- |如何通过数据找到创业的“上帝视角”?
- 小米12|小米Civi美女产品经理实锤:最便宜小米12版本被砍!
- 关注手机产品的朋友们|神仙秒充?小米12prok50电竞版申请注册
- 这样的F1第一视角你看过吗?开着红牛RB7跑山
- 小米 Civi 产品经理证实:没有小米 12 青春版了
- 「墨刀」UOS 版上架统信应用商店:在线产品设计协作