知识|产品视角下的知识图谱构建流程与技术理解( 四 )
这里需要引入一些概念,首先是本体(Ontology)和实例,本体原本是一个哲学概念,知识图谱中本体实际上就是对特定领域之中某套概念及其相互之间关系的形式化表达,实例就是本体的具体例子,这就像JAVA中的类和对象,类是本体,new一个对象是实例。
不同对象之间可能存在关系,而这就是一条边。
实体是本体、实例及关系的整合,比如“手机”是本体框中的一个概念,概念中也规定了相关属性比如“处理器”,苹果手机是一个具体的手机,叫做实例,所以苹果手机也有处理器,苹果手机以及体现苹果手机的本体概念“手机”以及相关属性,叫做一个实体。
大量实体的集合形成了知识库,例如DBpedia。这些实体通过语义相互连接,就形成了语义网络,而这也即是知识图谱的前身。
大部分情况下,人们将实体和概念统称为实体,将关系和属性统称为关系,对知识图谱进行了简化,这样知识图谱就变成了描述实体以及实体之间的关系的图结构。

文章插图
如果按照简化过的知识图谱定义,图谱中的两个节点和一条边就构成了一个实体,比如“水泥是建材的一个子类”,就可以表示为“水泥”和“建材”两个节点,以及一条由水泥指向建材的,属性为子类的有向边。
在图结构中,这样的边是可以快速添加的,而节点也都是可以快速添加的,这比传统的关系型数据库具有更高的灵活性,也更容易建模,修改的时候也不会造成太大的工作量。
图结构有专门的图数据库,目前知识图谱中应用的比较成熟的图数据库有Neo4J。Neo4J是一个近年来发展起来的图形化数据库,相对于关系型数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,图数据库中通过节点可直接查询,而关系型数据库中,需要通过多张表连接查询,产生性能上的问题。
Neo4J尤其对图算法进行了改进,查询和修改的速度较快,性能也可接受。
Neo4j还提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图,可以扩展到多台机器并行运行。Neo4j中实现的图查询语言是Cypher Quary Language,简称CQL。
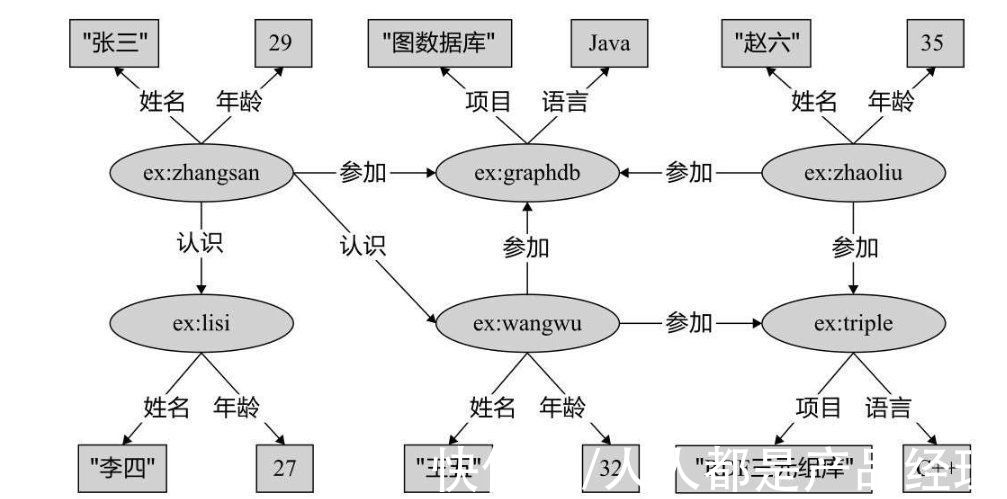
除了图结构,现在大部分知识图谱中采用的结构是三元组,是一种更容易存储、识别和利用的的数据结构。
简单来说,三元组就是知识图谱中的两个节点和一条边组成的关系对,或者说是一个实体。
要让计算机理解三元组,就必须对其进行规范化定义,这就引出了RDF(Resource Description Frame 资源描述框架)和Owl语言(Ontology Web Language 网络本体语言)等定义标准。
文章插图
图:三元组
RDF(Resource Description Frame 资源描述框架)是一个使用XML语法来表示的资料模型(Data model),是由W3C制定并推广的一套用于描述实体和关系的标准。
RDF使用统一资源标识(URI,Uniform Resource Indentifiers)来命名来标识资源,任何一个事物或概念,只要按照RDF表示法描述都可以成为一个资源。
有了资源之后,RDF使用属性和属性值来描述资源,属性和属性值定义了资源的形态。
特定的资源以一个被命名的属性与相应的属性值来描述,称为一个RDF陈述,其中资源是主词(Subject),属性是述词(Predicate),属性值则是受词(Object),需要注意的是,陈述的受词除了可能是一个字符串,也可能是其它的资料形态或是一个资源。
一个RDF实例
- |我依然是iPhone 6P的“钉子户”,尽管它成了古董产品
- |2022年换手机首选这款产品,性价比高运行速度快,用三四年没问题
- 基础层|B端决策类产品|关键信息密度提升设计
- 凌锋|追求更好用的轻薄本,还得看准Evo认证,这两款产品全都有
- |如何通过数据找到创业的“上帝视角”?
- 小米12|小米Civi美女产品经理实锤:最便宜小米12版本被砍!
- 关注手机产品的朋友们|神仙秒充?小米12prok50电竞版申请注册
- 这样的F1第一视角你看过吗?开着红牛RB7跑山
- 小米 Civi 产品经理证实:没有小米 12 青春版了
- 「墨刀」UOS 版上架统信应用商店:在线产品设计协作