知识|产品视角下的知识图谱构建流程与技术理解(12)
传统问答方法使用的主要技术包括关键词检索、文本蕴涵推理以及逻辑表达式等,深度学习方法使用的技术主要是LSTM、注意力模型与记忆网络(Memory Network)。
KBQA(knowledge base question answering,基于知识库的问答系统)采用了相对统一的基于RDF表示的知识图谱作为存储基础,并且把语义理解的结果映射到知识图谱的本体后生成SPARQL查询解答问题。
通过本体可以将用户问题映射到基于概念拓扑图表示的查询表达式,也就对应了知识图谱中某种子图。KBQA的核心问题Question2Query是找到从用户问题到知识图谱子图的最合理映射。
除了KBQA外,问答系统还有 CommunityQA/FAQ-QA(基于问答对匹配的问答系统)、 Hybrid QA Framework(混合问答系统框架)、基于深度学习的传统问答模块优化、基于深度学习的端到端问答模型,感兴趣的可自行查阅。
文章插图
图:问答系统
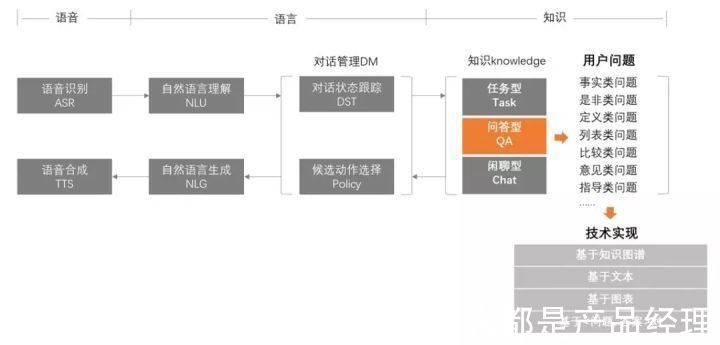
如果考虑在实际产品中涉及一个对话系统,通常需要考虑六大部分:
- [ 语音识别ASR ] 将原始的语音信号转换为文本信息;
- [ 自然语言理解NLU ] 将识别出来的文本信息转换为机器可以理解的语义查询;
- [ 对话管理DM ] 根据NLU模块输出的语义表示执行对话状态的跟踪,并根据一定的策略选择相应的候选动作。包括对话状态跟踪DST和候选动作选择Pollcy两部分;
- [ 自然语言生成NLG ] 负责生成需要回复给用户的自然语言文本;
- [ 语音合成TTS ] 将自然语言文本转换成语音输出给用户;
- [ 知识Knowledge ] 对话任务的完成离不开知识,不论是任务型中的意图及参数,问题型中的知识库,还是闲聊中的语料都属于知识(但是知识并不一定只有这三类)。对话系统结合知识后,能够形成完善的对话交互框架。
3. 推荐系统推荐系统是我们每天都能接触到的系统,如淘宝的千人千面,网易云音乐的个性化歌单,目前的个性化推荐算法中应用最广的是协同过滤算法。
协同过滤分为协同和过滤两个步骤,协同就是利用群体的行为来做推荐决策,而过滤就是从可行的推荐方案中将用户最喜欢的方案找出来。
通过群体的协同和每个用户是否喜欢推荐的反馈不断迭代,最终的推荐会越来越准确。
当前协同过滤算法主要包括基于用户的协同过滤和基于物品的协同过滤,其核心是怎么计算标的物之间的相似度以及用户之间的相似度。
将与当前用户最相似的用户喜欢的标的物推荐给该用户,这就是基于用户的协同过滤的核心思想;将用户操作过的标的物最相似的标的物推荐给用户,这就是基于标的物的协同过滤的核心思想。
推荐的过程可以简单理解为三个步骤:召回、过滤、排序。
- 首先系统根据获取到的信息,召回适合推荐内容,获取的信息可以是用户的搜索记录、购买记录、评论等。
- 召回的内容中有的是这个用户不关注的,需要根据过滤的条件,将不需要的内容进行过滤。
- 经过过滤产生的推荐集还需要根据内容的相关度进行排序,最后系统根据相关度的排序,将内容分配到对应的模块,这样用户就能看到自己感兴趣的内容了。
(1) 数据稀疏/长尾/噪音问题
用于协同过滤计算的用户行为矩阵(用户和其对应有交互(如购买,点赞,收藏等)的物品矩阵),必然是一个稀疏矩阵,用较小范围的数据推测较大范围的数据,会存在预测不准确的问题。
- |我依然是iPhone 6P的“钉子户”,尽管它成了古董产品
- |2022年换手机首选这款产品,性价比高运行速度快,用三四年没问题
- 基础层|B端决策类产品|关键信息密度提升设计
- 凌锋|追求更好用的轻薄本,还得看准Evo认证,这两款产品全都有
- |如何通过数据找到创业的“上帝视角”?
- 小米12|小米Civi美女产品经理实锤:最便宜小米12版本被砍!
- 关注手机产品的朋友们|神仙秒充?小米12prok50电竞版申请注册
- 这样的F1第一视角你看过吗?开着红牛RB7跑山
- 小米 Civi 产品经理证实:没有小米 12 青春版了
- 「墨刀」UOS 版上架统信应用商店:在线产品设计协作