除此之外,也进一步验证了以CAE为代表的MIM方法,要比Moco v3、DINO为代表的对比学习方法更适合下游任务。
该论文从随机裁剪操作的性质分析,认为随机裁剪有很大概率包含图像的中心区域。
而ImageNet-1K这种数据集中,中心区域通常是1000类标签集中的物体(如下图)。因此,对比学习方法主要提取图像中主体物体的特征。

文章插图
而MIM方法能学到每个patch的特征,包括图像的背景区域,而不仅仅是图像主体物体,这让MIM学到的表征更适合下游检测分割任务。
论文对CAE和MoCo v3的注意力图做了可视化。红色表示注意力值更高,蓝色表示注意力值更低。第一行是原图,第二行是 MoCo v3,第三行是 CAE。可以看到,MoCo v3 的注意力图主要在图像的主体区域有高响应,而 CAE 能考虑到几乎所有patch。
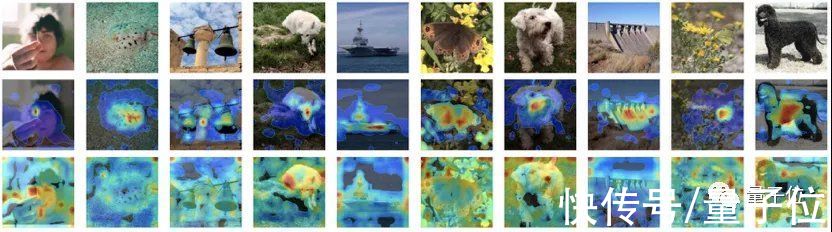
文章插图
实验结果研究团队使用ViT-small和ViT-base在 ImageNet-1K 上进行实验,输入图像的分辨率224*224,每张图被分成14*14的patch,每个patch的大小为16*16。
每次将有75个patch被随机掩码,其余patch则为可见的。
本文参照BEiT,使用DALL-E tokenizer对输入图像token化,得到预测目标。
最终结果显示,在语义分割任务中,跟其他MIM方法,比如MAE、BEiT,以及对比学习、有监督预训练方法的表征结果更好。
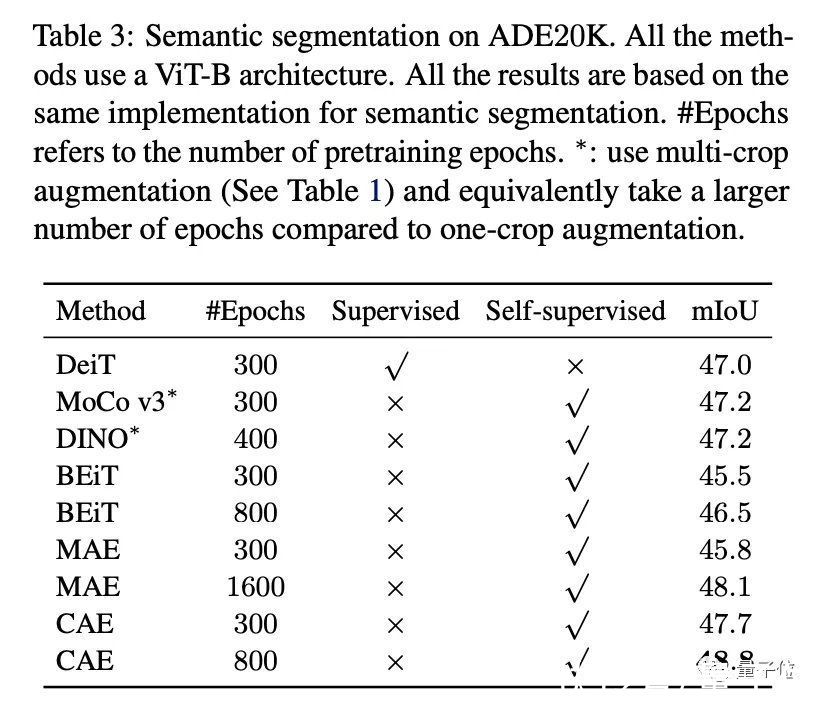
文章插图
在物体检测、实例分割的结果也是如此。
文章插图
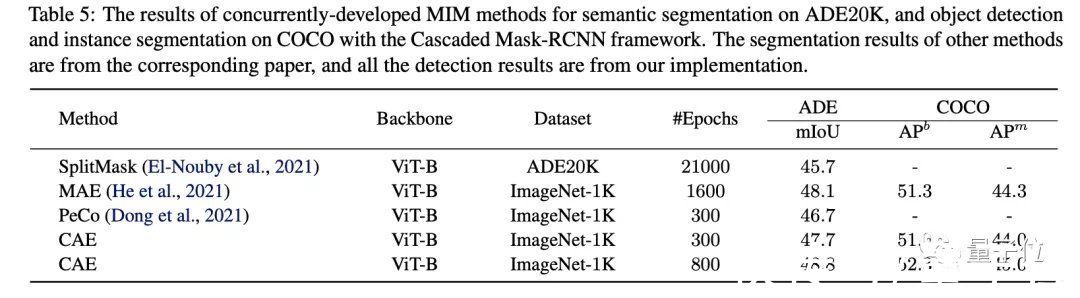
文章插图
百度CV大牛领衔本次研究由北京大学、香港大学、百度共同完成。
第一作者是在读博士生陈小康,来自北京大学机器感知与智能(教育部)重点实验室。
通讯作者是百度计算机视觉首席架构师王井东,同时也是IEEE Fellow。
在加盟百度之前,曾在微软亚研院视觉计算组担任首席研究员。

文章插图
感兴趣的旁友,可戳下方链接进一步查看论文~
论文链接:
https://arxiv.org/abs/2202.03026
— 完 —
量子位 QbitAI · 头条号签约
- 学院|北大正式成立智能学院,AI视觉大牛朱松纯任院长
- |北大研究团队发现水星存在磁暴与环电流
- 水星|北大研究团队发现水星存在磁暴与环电流
- https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律
- 硅谷|为什么去美国硅谷工作,成为很多清华北大毕业生的首选?
- 北大校友马里千:计算机视觉商用的下一个十年,AI 生成应占有一席之地
- 美国|光刻机只是个幌子?中科院攻克一项关键技术,美国提出无理要求
- IPO|矫正手术在很大程度上改变了原始面部信息,对面部识别算法提出了巨大挑战
- 让炼丹更玄学!苏大博士生用“天干地支”生成随机种子,项目已开源
- 微信|为什么去美国硅谷工作,成为很多清华北大毕业生的首选?