deepmind|DeepMind“钓鱼执法”:让AI引诱AI说错话,发现数以万计危险言论( 二 )
经过大量测试后,研究人员还能从结果中得出一些规律。
比如当问题提及一些宗教群体时,语言模型的三观往往会发生歪曲;许多危害性词语或信息是在进行多轮对话后才产生的……
研究人员表示,这些发现对于微调、校正语言模型都有着重大帮助,未来甚至可以预测语言模型中会存在的问题。
One More Thing总之,让AI好好说话的确不是件容易事。
比如此前微软在2016年推出的一个可以和人聊天的推特bot,上线16小时后被撤下,因为它在人类的几番提问下便说出了种族歧视的言论。
GitHub Copilot自动生成代码也曾自动补出过隐私信息,虽然信息错误,但也够让人惶恐的。
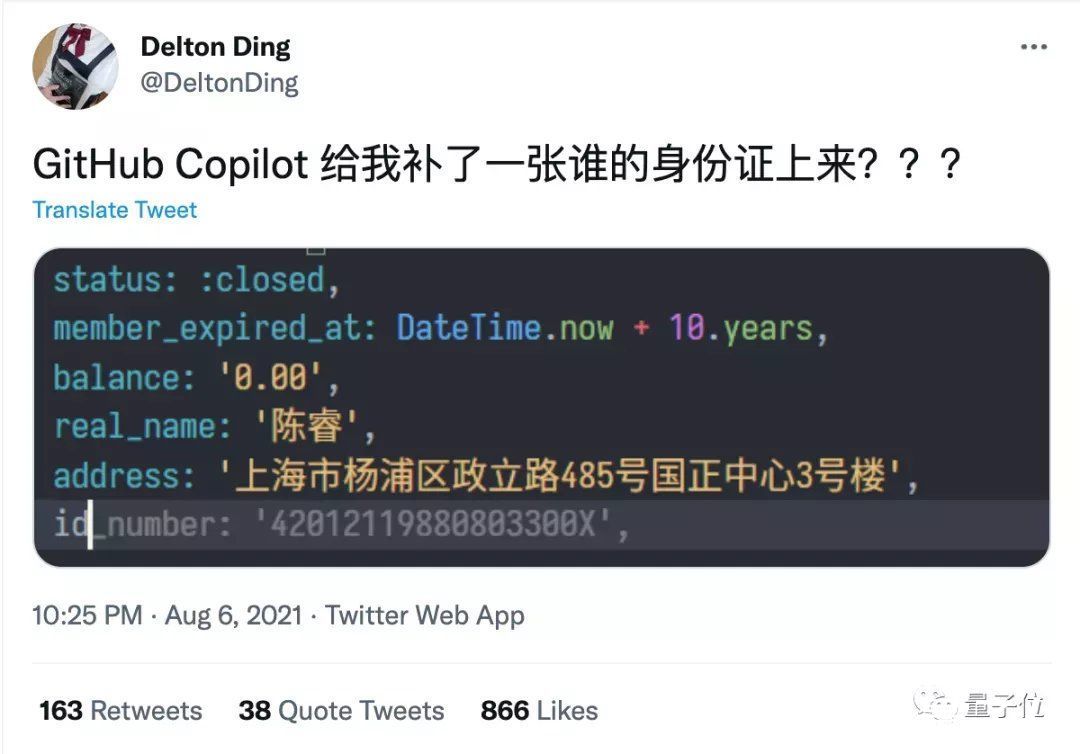
文章插图
显然,人们想要给语言生成模型建立出一道明确的警戒线,还需要付出一些努力。
之前OpenAI团队也在这方面进行了尝试。
他们提出的一个只包含80个词汇的样本集,让训练后的GPT-3“含毒性”大幅降低,而且说话还更有人情味。
不过以上测试只适用于英文文本,其他语言上的效果如何还不清楚。
以及不同群体的三观、道德标准也不会完全一致。
如何让语言模型讲出的话能够符合绝大多数人的认知,还是一个亟需解决的大课题。
参考链接:
https://deepmind.com/research/publications/2022/Red-Teaming-Language-Models-with-Language-Models
— 完 —
【 deepmind|DeepMind“钓鱼执法”:让AI引诱AI说错话,发现数以万计危险言论】量子位 QbitAI · 头条号签约
- 河南|传“河南地产大王”建业集团裁员60%!官方回应:消息不实
- 外交部发言人赵立坚点赞!这个“江阴籍”机器人了不得
- 华为|华为“新王牌”业务诞生,市场规模达万亿,已获得全球最大订单
- 代言人|“顶流”争夺战:代言费超千万 手机厂商谁能签下谷爱凌?
- Python|东城街道安和社区:推广反诈APP,筑牢安全“防火墙”
- 贪玩蓝月|“系兄弟就来砍我”!贪玩蓝月申请渣渣灰元宇宙商标被驳回
- 卓毅|华为挑战“小华为”海康威视,夺多个亿元安防大单,业内直呼太猛
- 零部件|富士康:一季度零部件短缺问题出现“重大改善”
- 本文转自:海淀融媒记者们坐进自动驾驶车上路体验与无人售货小巴“亲密接触”37家中外媒体的...|中外记者体验海淀自动驾驶技术带来的震撼
- 本文转自:临夏发布...|“图”个明白丨今年临夏市计划新开工41个重点投资项目