vit|Meta AI发布图音文大一统模型Data2vec,CV精度超MAE( 二 )
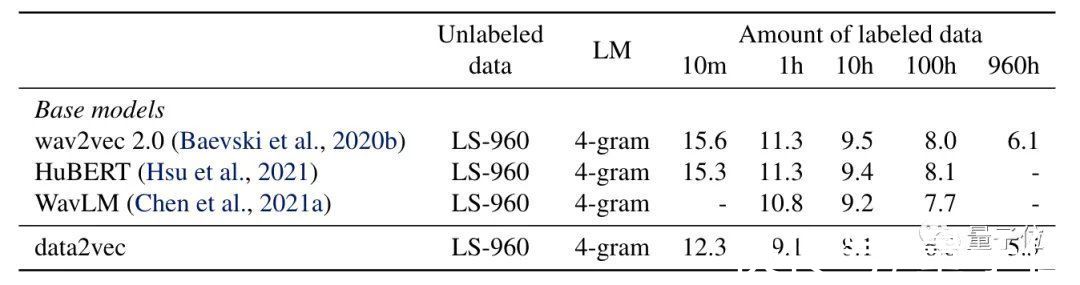
文章插图
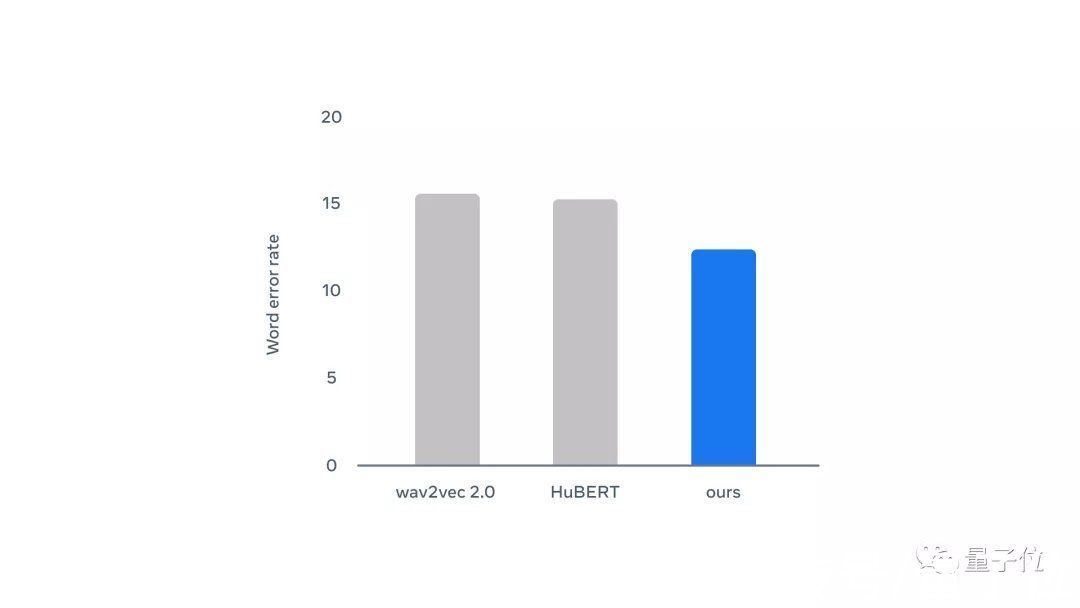
可以看出,Data2vec在不同的标签数据量下单词错误率都比wav2vec2.0和HuBERT要低。
文章插图
在GLUE评估中,Data2vec在自然语言推理(MNLI、QNLI、RTE),句子相似性(MRPC、QQP、STS-B),语法(CoLA)和情绪分析(SST)等指标中和RoBERTa不相上下。
其中Baseline这一条是RoBERTa在和BERT类似的设置中的训练结果:
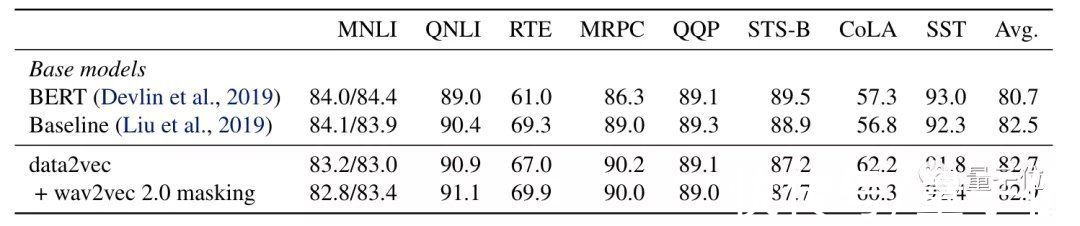
文章插图
总体评分也差不多:
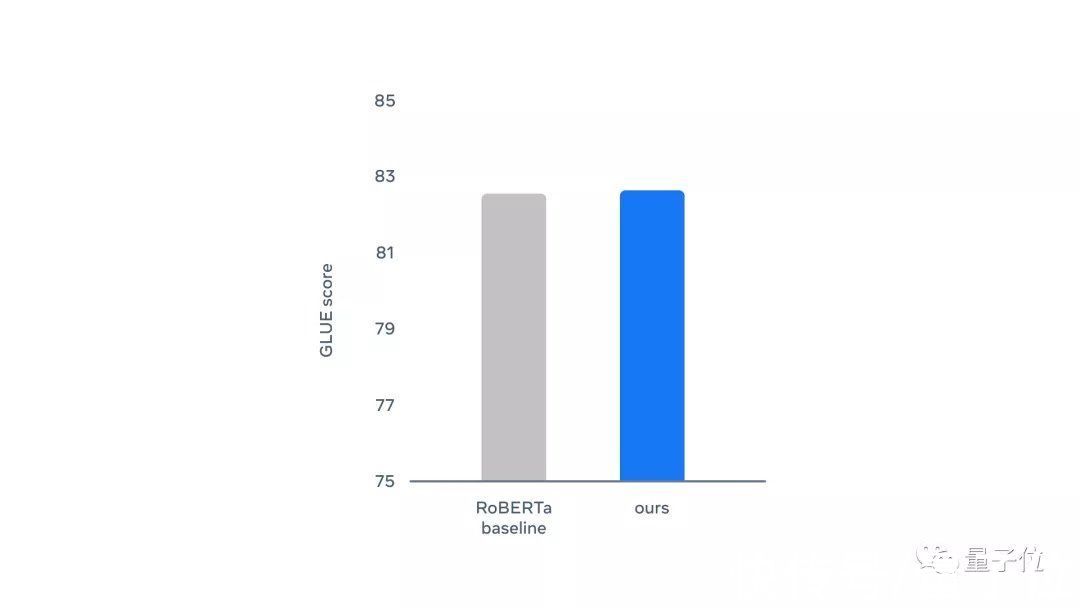
文章插图
这么看来,统一的模型架构真的可以有效地用于多种任务模式。
虽然Data2vec在输入数据和掩码方式上还是按照不同的方法来处理,但是它仍然是探索模型统一的尝试。
或许将来会有统一的掩码策略和不同模态数据的混合数据集,做到真正的大一统。
参考链接:
[1]https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
[2]https://ai.facebook.com/blog/the-first-high-performance-self-supervised-algorithm-that-works-for-speech-vision-and-text
[3]https://github.com/pytorch/fairseq/tree/main/examples/data2vec
- 小米科技|三星2月9日举办发布会,S22 Ultra配置大升级!起售价8000+
- 三星|三星释出发布会邀请函,S22系列价格也被曝出,引网友热议!
- AirPods|苹果AirPods Pro将于2022年发布,你最期待哪些变化?
- 操作系统|美国系统被抛弃了?华为之后,国家入局,又一国产系统正式发布
- 事关冷链食品和进口水果!昆明发布最新通知
- 闪存|「先见」聊聊年后发布的拯救者电竞手机 Y90:又是明升暗降
- 三星Galaxy|三星Galaxy Tab S8系列PPT提前泄漏,发布会还需要开吗?
- 世纪互联|360发布百亿红包计划 网友猜测或是周鸿祎直播首秀
- 网络安全|iOS 15.4发布,背刺的却是Apple Watch用户?
- 拓维信息开鸿智谷全场景智慧教室发布