Jeff De2021谷歌年度 Jeff( 三 )
这些模型通常使用自监督学习方法进行训练,其中模型从未经标记的“原始”数据的观察中学习,例如 GPT-3 和 GLaM 中使用的语言模型、自监督语音模型 BigSSL 、视觉对比学习模型 SimCLR 和多模态对比模型 VATT。自监督学习让大型语音识别模型得以达到之前的语音搜索自动语音识别 (ASR) 基准的准确度,同时仅使用 3% 的带注释训练数据。
这些趋势令人兴奋,因为它们可以大大减少为特定任务启用机器学习所需的工作量,并且由于使得在更具代表性的数据上训练模型变得更容易,这些数据更好地反映了不同的亚群、地区、语言,或其他重要的表示维度。
所有这些趋势都指向训练功能强大的通用模型的方向,这些模型可以处理多种数据模式,并解决成千上万个任务。通过构建稀疏性模型,使得模型中唯一被给定任务激活的部分,仅有那些为其优化过的部分,从而这些多模态模型可以变得高效。
Jeff Dean表示,在接下来的几年里,谷歌将基于Pathways架构追求这一愿景。
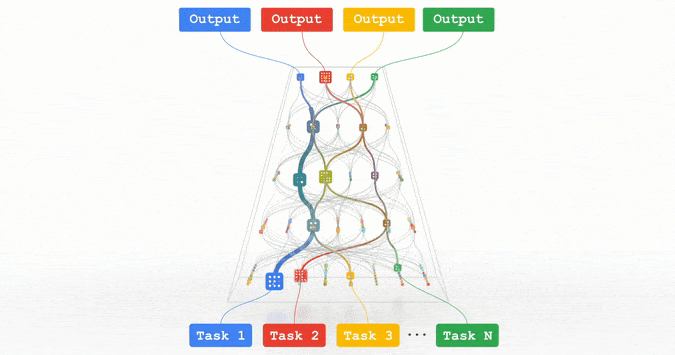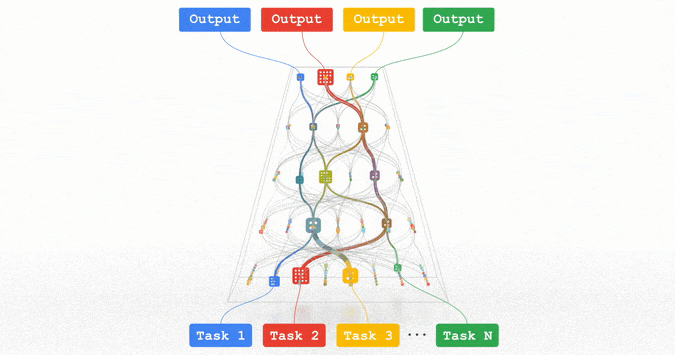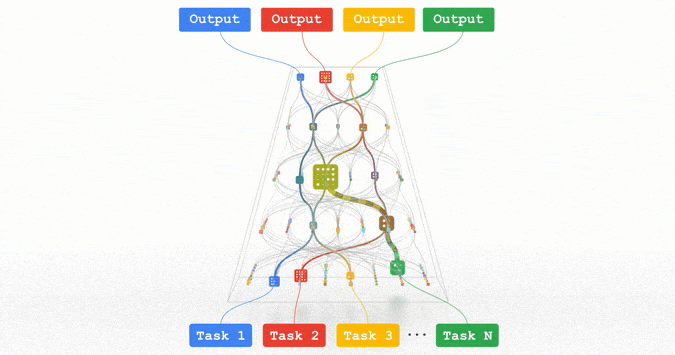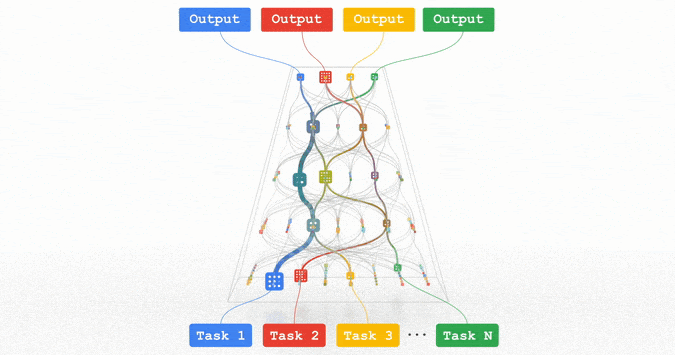
文章插图
Pathways:谷歌正在努力的统一模型,可以泛化至数百万个任务。
ML 流水线涉及许多方面,从训练和执行模型的硬件,到 ML 架构的各个组件,都可以进行效率优化,同时保持或提高整体性能。
与前几年相比,这些线程中的每一个都可以以显著的乘法因子提高效率,并且综合起来可以将计算成本(包括二氧化碳当量排放量)降低几个数量级。
更高的效率促成了许多关键的进步,这些进步将继续显著提高机器学习的效率,使更大、更高质量的机器学习模型能够以高效的方式开发,并进一步使访问公平化。
ML 加速器性能的持续改进
每一代 ML 加速器都在前几代的基础上进行了改进,使每个芯片的性能更快,并且通常可以扩大整个系统的规模。
去年,谷歌发布了其TPUv4 系统,这是谷歌的第四代张量处理单元,它在 MLPerf 基准测试中比 TPUv3 提升了 2.7 倍。TPUv4 芯片的峰值性能是 TPUv3 芯片的约 2 倍,每个 TPUv4 pod 的规模为 4096 个芯片(是 TPUv3 pod 的 4 倍),每个 pod 的性能约为 1.1 exaflops(而每个 TPUv3 pod约为 100 petaflops)。拥有大量芯片并通过高速网络连接在一起的 Pod 可以提高大型模型的效率。
此外,移动设备上的机器学习能力也在显着提高。Pixel 6 手机采用全新的 Google Tensor 处理器,该处理器集成了强大的 ML 加速器,以更好地支持重要的设备功能。

文章插图
左:TPUv4 主板;中:TPUv4 pod的一部分;右图:在 Pixel 6 手机中的 Google Tensor 芯片。
Jeff Dean表示,谷歌使用 ML 来加速各种计算机芯片的设计也带来了好处,特别是在生产更好的 ML 加速器方面。
ML 编译和 ML 工作负载优化的持续改进
即使硬件不变,编译器的改进和机器学习加速器系统软件的其他优化也可以显著提高效率。
例如,“A Flexible Approach to Autotuning Multi-pass Machine Learning Compilers”展示了如何使用机器学习来执行编译设置的自动调整,用于同一底层硬件上的一套 ML 程序,以获得 5-15% 的全面性能提升(有时甚至高达2.4 倍改进)。
- Pixel|2800元的谷歌Pixel 5a成老外眼中最好的手机之一:可惜没人关注
- 谷歌Pixel|谷歌Pixel 6 Pro经常没信号:官方推送更新修复
- Java|假如让谷歌浏览器进入中国市场,国产浏览器会受到很大影响吗?
- Pixel|致敬OPPO Find N!谷歌折叠屏曝光:价格不到11000元
- Pixel|近6000块的谷歌Pixel 6 Pro被知名博主吐槽:体验太差 换回S21 Ultra
- 搜索引擎|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 谷歌|Alphabet赋予其他子公司更大自主权,不效仿谷歌架构
- 英特尔|欧洲消费者:放弃使用谷歌软件而使用华为软件,几乎不可能发生
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- Google|为何谷歌地图能一家独大?收购多家公司,资金实力领先众多企业