Jeff De2021谷歌年度 Jeff( 十 )
谷歌也在关注自然灾害预防。去年,他们推出了由卫星数据提供支持的野火边界图,以帮助人们直接通过设备轻松了解火灾的大致规模和位置。
在此基础上,研究人员现在将谷歌的所有野火信息整合在一起,并在全球范围内推出谷歌地图上的新图层。他们一直在应用图形优化算法来帮助优化火灾疏散路线。
2021 年,谷歌首次在实际的洪水预警系统中部署了基于 LSTM 的预测模型和新的模型( Manifold inundation model)。

文章插图
图注:Google 地图中的野火层可在紧急情况下为人们提供重要的最新信息。
ML 模型训练的碳排放是 ML 社区关注的问题,谷歌已经证明了关于模型架构、数据中心和 ML 加速器类型的选择可以将训练的碳足迹减少约 100-1000 倍。
基于在线产品中的用户活动的推荐系统就是其中一个。通常推荐系统是由多个不同组件构成的,想要理解它们的公平属性,需要了解各个组件以及它们组合时的运行方式。
谷歌最新的研究提高了单个组件和整体推荐系统的公平性,帮助用户更好地理解这些“关联性”。而且,在从匿名用户活动中学习时,推荐系统以“中立”的方式学习至是十分必要的。从先前用户的数据中直接学习到的“经验”,可能带有显而易见的“偏见”。如果不纠正,那新用户可能会频繁收到不符合心意的产品推荐。
与推荐系统类似,上下文环境在机器翻译中至关重要。大多数机器翻译系统都是孤立地翻译单个句子,没参考额外的上下文内容,无意间添加了性别、年龄等“歧视”属性。谷歌去年公布了一个专门针对翻译中性别偏见的数据集,用来研究基于维基百科传记的翻译偏见。
部署机器学习模型中另一个常见问题是分布偏移(distributional shift):如果训练模型数据的统计分布与输入模型数据的统计分布不同,可能造成模型产生的结果不可预测。
谷歌利用 Deep Bootstrap 框架对比有限训练数据的现实世界与无限数据的“大同世界”。从而更好地理解模型的行为(真实中与理想中的世界),研究人员可以开发泛化性更强的模型,对固定训练数据集减少“偏见”。
虽然机器学习算法和模型开发一直备受关注,但数据收集和数据集管理类的工作相对较少。毋庸置疑,它们是不可忽视的领域,因为训练机器模型所依据的数据可能是下游应用程序中公平性问题的潜在来源。分析机器学习中此类数据级联,将有助于识别项目周期中对结果产生重大影响的许多因素。
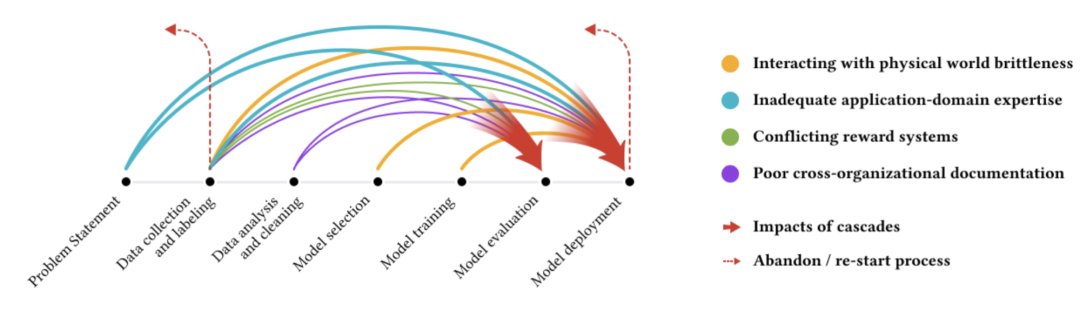
文章插图
图注:不同颜色的箭头表示各种类型的数据级联,每个级联通常起源于上游,在ML开发过程中复合,并在下游呈现。
更好地理解数据是机器学习研究的一个核心环节。谷歌开发了一类方法能够深入了解特定训练示例对机器学习模型的影响,因为错误标记的数据或其他类似问题对整体模型都有巨大负面影响。谷歌还构建了Know Your Data 工具,用以帮助研究人员和从业者掌握数据集属性,例如:如何使用 Know Your Data 工具来探索性别、年龄偏见等问题。
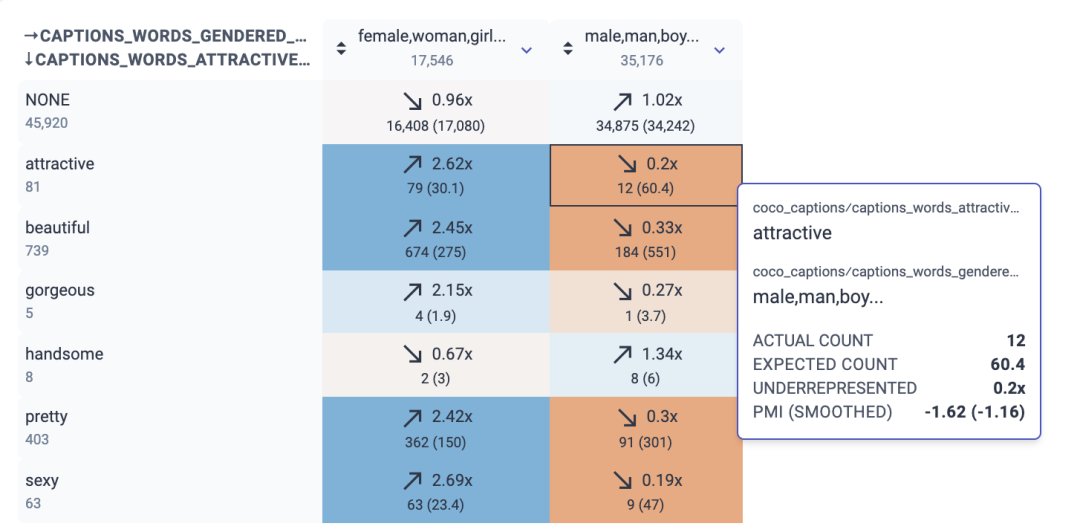
文章插图
图注:Know Your Data 的数据显示了描述吸引力的词与性别词之间的关系
- Pixel|2800元的谷歌Pixel 5a成老外眼中最好的手机之一:可惜没人关注
- 谷歌Pixel|谷歌Pixel 6 Pro经常没信号:官方推送更新修复
- Java|假如让谷歌浏览器进入中国市场,国产浏览器会受到很大影响吗?
- Pixel|致敬OPPO Find N!谷歌折叠屏曝光:价格不到11000元
- Pixel|近6000块的谷歌Pixel 6 Pro被知名博主吐槽:体验太差 换回S21 Ultra
- 搜索引擎|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 谷歌|Alphabet赋予其他子公司更大自主权,不效仿谷歌架构
- 英特尔|欧洲消费者:放弃使用谷歌软件而使用华为软件,几乎不可能发生
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- Google|为何谷歌地图能一家独大?收购多家公司,资金实力领先众多企业