趋势|谷歌大神 Jeff Dean 领衔,万字展望五大AI趋势( 四 )

文章插图
图丨与普通的 Transformer 模型相比,NAS 发现的 Primer 架构的效率是前者的4倍。这幅图(红色部分)显示了 Primer 的两个主要改进:深度卷积增加了注意力的多头投影和 squared ReLU 的激活(蓝色部分表示原始 Transformer)。
NAS 还被用于发现视觉领域中更有效的模型。EfficientNetV2 模型体系结构是神经体系结构搜索的结果,该搜索联合优化了模型精度、模型大小和训练速度。在 ImageNet 基准测试中,EfficientNetV2 提高了 5 到 11 倍的训练速度,同时大大减少了先前最先进模型的尺寸。CoAtNet 模型架构是通过一个架构搜索创建的,该架构搜索采用了视觉 Transformer 和卷积网络的想法,以创建一个混合模型架构,其训练速度比视觉 Transformer 快 4 倍,并取得了新的 ImageNet 技术水平。
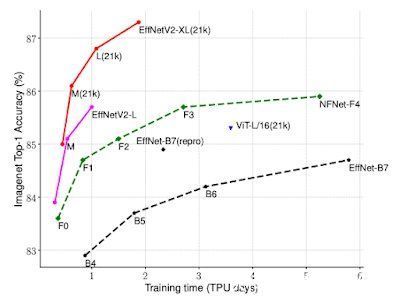
文章插图
图丨与之前的 ImageNet 分类模型相比,EfficientNetV2 获得了更好的训练效率。
搜索的广泛应用有助于改进 ML 模型体系结构和算法,包括强化学习(RL,Reinforcement Learning)和进化技术(evolutionary techniques)的使用,激励了其他研究人员将这种方法应用到不同的领域。为了帮助其他人创建他们自己的模型搜索,我们有一个开源的模型搜索平台,可以帮助他们探索发现其感兴趣的领域的模型搜索。除了模型架构之外,自动搜索还可以用于发现新的、更有效的强化学习算法,这是在早期 AutoML-Zero 工作的基础上进行的,该工作演示了自动化监督学习算法发现的方法。
稀疏的使用:
稀疏性是算法的另一个重要的进步,它可以极大地提高效率。稀疏性是指模型具有非常大的容量,但对于给定的任务、示例或 token,仅激活模型的某些部分。2017 年,我们推出了稀疏门控专家混合层(Sparsely-Gated Mixture-of-Experts Layer),在各种翻译基准上展示了更好的性能,同时在计算量上也保持着一定的优势,比先前最先进的密集 LSTM 模型少 10 倍。最近,Switch Transformer 将专家混合风格的架构与 Transformer 模型架构结合在一起,在训练时间和效率方面比密集的 T5-Base Transformer 模型提高了 7 倍。GLaM 模型表明,Transformer 和混合专家风格的层可以组合在一起,可以产生一个新的模型。该模型在 29 个基准线上平均超过 GPT-3 模型的精度,使用的训练能量减少 3 倍,推理计算减少 2 倍。稀疏性的概念也可以用于降低核心 Transformer 架构中注意力机制的成本。

文章插图
图丨BigBird 稀疏注意模型由全局 tokens(用于处理输入序列的所有部分)、局部 tokens(用于处理输入序列的所有部分)和一组随机 tokens 组成。从理论上看,这可以解释为在 Watts-Strogatz 图上添加了一些全局 tokens。
就计算效率而言,在模型中使用稀疏性显然是一种具有很高潜在收益的方法,而就在这个方向上进行尝试的研究想法而言,我们只是触及了表面。
这些提高效率的方法中的每一种都可以结合在一起,这样,与美国平均使用 P100 GPUs 训练的基线 Transformer 模型相比,目前在高效数据中心训练的等效精度语言模型的能源效率提高了 100 倍,产生的 CO2e 排放量减少了 650 倍。这甚至还没有考虑到谷歌的碳中和(carbon neutral),100% 的可再生能源抵消。
趋势3:机器学习正变得对个人和社区更加有益随着 ML 和硅硬件(如 Pixel 6 上的 Google Tensor 处理器)的创新,许多新体验成为可能,移动设备能够更持续有效地感知上下文和环境。这些进步提高了设备的可访问性和易用性,同时计算能力也有提升,这对于移动摄影、实时翻译等流行功能至关重要。值得注意的是,最近的技术进步还为用户提供了更加个性化的体验,同时加强了隐私保护。
- 沉浸式|海外观察丨未来 10 大科技趋势预测全解读(上)
- ROE雷迪奥到访芯映光电,共谈行业趋势,谱写合作新篇章
- Pixel|2800元的谷歌Pixel 5a成老外眼中最好的手机之一:可惜没人关注
- 谷歌Pixel|谷歌Pixel 6 Pro经常没信号:官方推送更新修复
- Java|假如让谷歌浏览器进入中国市场,国产浏览器会受到很大影响吗?
- Jeff De2021谷歌年度 Jeff
- Pixel|致敬OPPO Find N!谷歌折叠屏曝光:价格不到11000元
- Pixel|近6000块的谷歌Pixel 6 Pro被知名博主吐槽:体验太差 换回S21 Ultra
- 生意|“电商节”遇冷趋势下,品牌生意增量场在哪?
- 搜索引擎|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌