在 2022 年,当我们再次谈起数据湖和数据仓库的融合问题时,包含以上关键点的“智能湖仓”架构,很可能成为被业内重点参考的构建思路之一。
更强的数据安全、治理和数据共享能力
数据的安全、治理和共享,原是大数据的本职任务,但当数据达到 PB 乃至 EB 级,需要跨多个区域、组织、账户进行数据共享或数据交互时,企业有些时候并非不想细颗粒度管理数据,而是无法管理。这种颗粒度的权限控制往往比单机系统设计或者单一的分布式系统要复杂得多。所以,数据治理成为了“智能湖仓”重要的发力点。
在 2021 亚马逊云科技 re:Invent 大会上,支撑数据统一治理和自由流动能力的“智能湖仓”组件 Amazon Lake Formation 发布了多项新功能。除了之前早已支持的表和列级安全,Amazon Lake Formation 现在支持行和单元级权限,通过只限制用户对部分数据的访问权限,让限制访问敏感信息变得更加简单。
此外,Data mesh 的概念在 2021 亚马逊云科技 re:Invent 大会上也被提及。Data mesh 概念也是 Gartner 提出的十大数据技术趋势之一。在 Data mesh 模式下,“智能湖仓”能够实现领域数据成为产品、轻松启用细粒度授权、数据更容易被使用、数据调用跨企业可见和联邦的数据管控与合规。这意味着,“智能湖仓”架构下,Data mesh 可以实现跨数据湖的数据共享和计算。亚马逊云科技借助自身数据湖安全、tag 级别的访问控制和共享能力,为 Data mesh 提供了实现方式与手段,让 Data mesh 概念走向落地。
更敏捷的构建方式
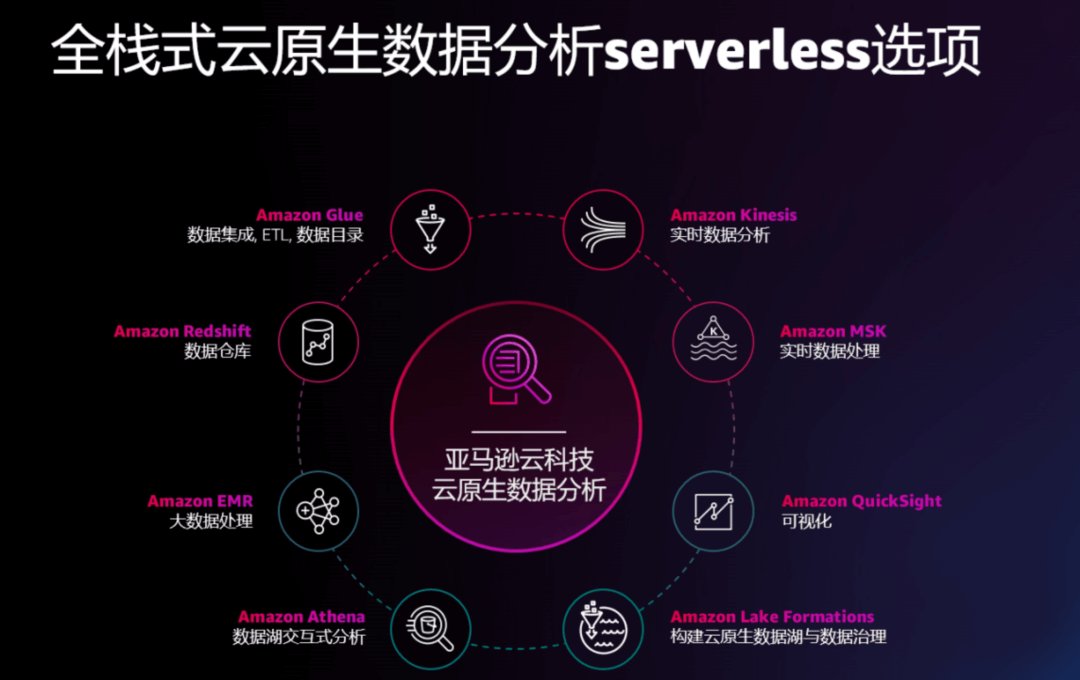
除了更强的数据安全、治理和数据共享能力,更敏捷的构建方式也是绝大多数企业当下主要关注的技术创新之一。敏捷在企业间的认可度和应用程度越来越高,而“智能湖仓”原本就是敏捷的架构。在“智能湖仓”架构中,Amazon Lake Formation 能够将建立数据湖的时间从数月缩短到数天。用户可以使用像 Amazon Glue 这样的 Serverless 数据集成工具快速实现数据入湖;使用 Amazon Athena 这样的 Serverless 查询引擎直接实现基于 SQL 语言的湖上数据查询分析。无论是超大型公司还是工作室,都可以从这种敏捷的构建方式中快速获益,提取数据的价值。
为了让构建方式更敏捷,在 2021 亚马逊云科技 re:Invent 大会上,亚马逊云科技宣布推出更多数据分析服务的无服务器版,借助无服务器的能力,让用户可以更敏捷地构建自己的数据存储、分析、智能应用解决方案。
- Amazon Redshift Serverless ,让数据仓库更敏捷,支持在几秒钟内自动设置和扩展资源,用户无需管理数据仓库集群,实现 PB 级数据规模运行高性能分析工作负载;
- Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless ,让流式数据接入与处理,支持快速扩展资源,简化实时数据摄取和流式传输,实现全面监控、移动甚至跨集群加载分区,自动调配和扩展计算和存储资源,让用户可以按需使用 Kafka;
- Amazon EMR Serverless 让大数据处理更敏捷,用户无需部署、管理和扩展底层基础设施,使用开源大数据框架(如 Apache Spark、Hive 和 Presto)运行分析型应用程序;
- Amazon Kinesis Data Streams on Demand 让流式数据分析与实时数据场景搭建更敏捷。每分钟可以处理数 GB 的写入和读取吞吐量,而不必预置与管理服务器、存储,在成本和性能之间取得平衡且变得更加简单。
文章插图
来自亚马逊云科技的数据显示,现在每天有数以万计的用户每天在使用 Amazon Redshift 处理超过 2EB 的数据。全球最大的制药公司之一罗氏制药(Roche)首席云平台和机器学习工程师 Yannick Misteli 博士表示:“Amazon Redshift Serverless 可减轻运营负担,降低成本,并帮助罗氏制药规模化实践 Go-to-Market 策略。这种极简的方式改变了游戏规则,帮助我们快速上手并支持各种繁重的分析场景。”
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 苹果|从5499元跌至3399元,苹果A14+IP68防水,旧款iPhone加速清仓
- 小米科技|从4999跌至2889元,2K曲面屏+IP68防水,小米老款旗舰售价大跳水
- 骁龙855|从3499元跌至1190元,5000mAh+骁龙855,适合玩游戏
- iqoo neo|开始退场!红米K40最强对手清仓:高通870+独显,直降300历史最低
- 京东|国资入场!从80亿增加到300亿,蚂蚁金融的“改变”已经开始
- 60秒长语音不用再从头听了!微信迎来“史诗级更新”
- 阿里巴巴|被苹果无辜“踢出局”,引发央视点名,国产制造该何去何从?
- 马化腾|从不大放厥词,马化腾:腾讯随时被替换
- 飞天茅台|从3499元跌至2799元,100W快充+鸿蒙OS,还有5000万像素四摄