所以云天励飞在内部打造了一套标准化、流程化、平台化的研发方式。
什么叫流程化?
流程化的英文叫Streamline。不需要切换上下文就可以把所有的事情做完,现在美国的创业非常流行这样做,RPA也是同样的思路,做机器人流程自动化,把业务的流程放在无缝衔接的框架下完成。
只有在这种情况下,效率才是最高的,不需要一会儿做这个事,一会儿做那个事,频繁切换会影响工作效率。
标准化(standardization),把里面跟模型相关的非标准化的部分全部呈现在技术上,整个平台上只剩下标准化的东西。
这样做的好处是什么?容易学习,所以不需要博士做这个事情,可能本科生甚至是高中生就可以干这个事,从而把博士资源放在更紧要的地方。
平台化(platform),这也是整个软件行业的趋势。
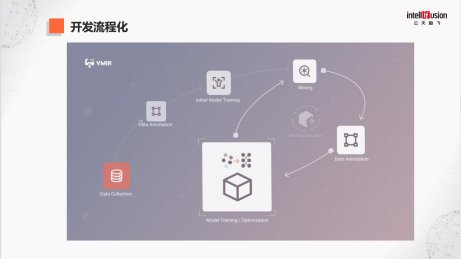
文章插图
这张图是我们大规模算法研发的流程:
第一步,搜集数据,这时候数据是没有标注的。
第二步,做数据标注;
第三步,模型训练;
第四步,data mining,有了初始模型后,在海量没有标注的数据里找到可以提高性能的数据;
第五步,再进行标注。
如果把这个平台分成三步,前两步就是做初始模型的建立,后面就是做完整闭环,像飞轮一样,它在不停地转,每转一次都可以得到更好的精度。这个转法是在我们平台上实现的,不需要专家级别的人专门来做。
第一步,获取初始模型。
首先我们有分布式标注平台,开发人员可以定义一个任务。比如做街道下水道井盖有没有被人拿走的检测,也许我们会标注10-20个数据。
标注之后怎么办?这是学术界和工业界很火的大模型和无监督学习。
为什么我们在这里面放了大模型和无监督学习?刚才我们讲到,一开始我们想做井盖被人拿走的事实检测,我们一开始可能没有这么多标注好的数据,可能只有100个,但数据标注的效率可能是万分之一。
如果你想标1万个这样的数据,需要标1亿个data,这个量非常大。怎么办?
先标100个,为什么要用大模型和无监督学习配合这个数据去跑模型?就是为了让你初始模型的精度达到最高。
无监督和大模型最好的方式,本来100个数据训练出来的精度只有30%,用大模型和无监督学习的方法训练之后,精度可以达到80%,那挖掘数据的效率可以提高10倍,也就是说我少标了10倍的数据,一切都是为了后面数据迭代的效率来做的。
为什么大模型和无监督学习可以提高这个性能?虽然它自己没有标注数据,但它是被千亿、百亿级的数据训练出来的,知道井盖是什么样的,这种特征的编辑其实已经实现了,再配合少量数据的标注,就可以得到一个还不错的初始模型。
为什么要得到还不错的初始模型?因为数据迭代的效率会更高,首先是为了第一步方便。
第二步,我们不说模型迭代,而是数据迭代,因为我们认为模型的训练已经被标准化了,在平台上,点个按钮它就训练好了,不需要有模型训练的知识,我们专家的系统已经把它做好了。
所谓的数据迭代,就是在海量还没有标注好的数据中,找到能够提高模型性能的数据,进行主动学习。
传统模型研发的范式是缺数据再去标,但发现标过来的数据跟以前的分布是一样的,对模型的分布没有太大用处。所以需要用技术、算法找到对自己真正有用的数据,右边我们从海量数据中找出了9张有用的数据。
模型挖掘怎么做?在左边平台界面,点一个按钮,选一个数据集,可以自动在这里面挖掘,从几亿的数据里找到几张跟井盖相关的数据做训练,我们是用主动学习算法做数据择优的。
- 2022年1月11日下午|国术科技携标准化产品——国术Eyeplay商用游戏机器人参加第二届中关村国际标准化主题周活动
- 薪资|公司想采购人事薪资系统,是选标准化软件、还是定制开发(买断)?差别在哪?
- 京东云携手智云天工、小田实业共建智能制造产业园
- 电子商务|2021年终盘点|二手电商交易标准化体系逐渐成型,行业头部效应凸显
- 国务院办公厅|国务院办公厅:推动人工智能、区块链、车联网等领域数据采集标准化
- 实力| 实力认证!薪宝科技获全球国际标准化组织ISO27001认证
- 《仙剑奇侠传4》云天河人偶开启众筹 标准版1180元
- 京东科技与智云天工共创智造新模式 常州落地效果显著
- 新智造 新模式 京东科技与智云天工达成战略合作
- 企业如何开展安全生产标准化自查评(46页)(附下载)